A long while back I wrote a PowerShell script to produce a CSV file of EC2 instances across multiple accounts. The original PowerShell script was running on a Windows server as a scheduled task, oh how we have moved on. About 6 months ago I rewrote the script in Python and then moved it over to AWS Lambda. This was my first really opportunity to use AWS Lambda to execute code in a (Misnomer alert!!) serverless compute service.
AWS Services
The full process makes use of a number of AWS services.
- AWS Lambda for the code execution
- AWS S3 as storage for the output CSV
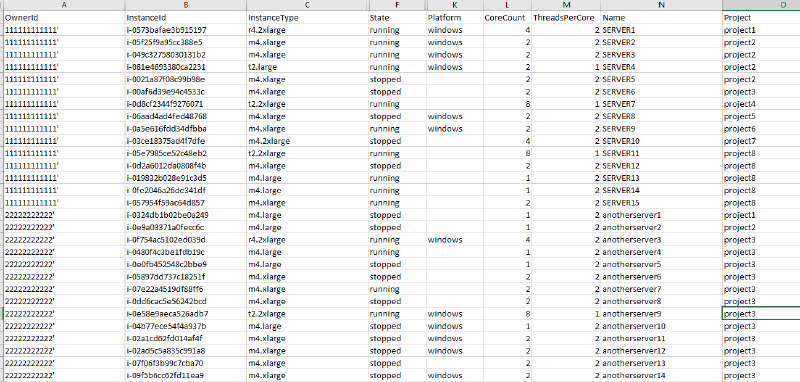
Output example
The report produces a CSV file similar to the below screenshot.
Input
The output CSV file is constructed using input variables provided as variables to AWS Lambda. Define the attributes and tags and accounts you wish to include in the report in the AWS Lambda console page.
Lambda Environment variables
To ensure the code can easily be re-used, all the key elements are variables. These can then be updated by anyone without having to get involved in the coding side. e.g. adding a new account or tag can easily be done by updating the comma separated list for the item within the Lambda environment variables.
| Key | Value |
|---|---|
| arole | role name to assume |
| attributes | (comma separated list) e.g. OwnerId,InstanceId,InstanceType |
| tags | (comma separated list) e.g. Name,Project,Release,Environment,CostCentre |
| aws_accounts | (comma separated list) e.g. 1111111111111,2222222222222,3333333333333 |
| bucket_name | name of bucket e.g. reporting_test_bucket |
| output_path | folder within the bucket where the report will be held. E.g. ec2_reports |
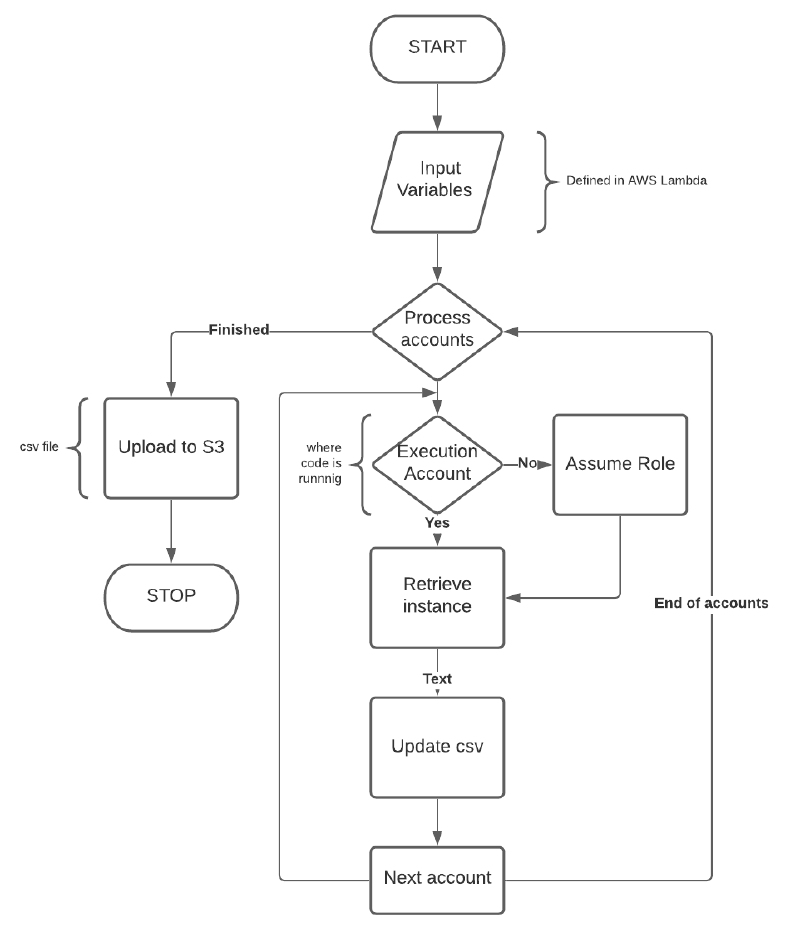
Flow Chart
This is what the process flow looks like
Code construct
Lets take a look at the code before we move into how its all executed
Imports
Import all of the required external libraries. The ones we are using are all already available in Lambda so no library additions are required.
|
|
Variables
The in-code variables have been setup to read from AWS Lambda environment variables. The variables prefixed with os.environ are retrieving the environment variables from the server (the serverless one 😄 )
Any hard coded variables are there as I have not yet updated the code to process the options so they are not configurable at this point. For example the report_format from my initial Python code handles “formatted” (used in this code) and also “RAW” which dumps all values from the instances. That will follow on at some point. It was requested by someone but I never really liked the output, messy.
|
|
Functions
As usual, lets add functions to allow for repeatable script blocks. Note that a number of the functions are similar to those used in the Terminate EC2 instance by tag using Python post. Why re-invent the wheel!
assume_roles
If the AWS account being processed is not the AWS account the script is being executed from, you will need to assume a role defined in that target account.
|
|
get_instances
No filtering being done this time around. We are retrieving the defined attributes from all instances in each AWS account listed.
|
|
formatted_report
This function is pulling in the attributes and tags we requested as environment variables. We are then creating a list of attributes and a list of tags. This makes it easier to perform the next function which writes out the CSV file. The two lists will makeup the fieldnames value for defining the column header which will be used in the proceeding function
|
|
report_writer
The report_writer function handles the output. All of the following items are handled in this function
The file type, file name, what the header will be
- File type
- File name
- fields to include
- header row
- Some of the retrieved values need a little nudging (post processing) before adding them
|
|
lambda_handler
The lambda_handler is what AWS Lambda invokes when the script is executed. This is the main function which when called will invoke the preceding functions.
|
|
Security
Script execution
For each of the AWS accounts that are assuming the role, the role will need to exist in that account. The same role name must be used in each AWS account you are querying. The role must trust the account which the assume is called and have at a minimum Read Only EC2 access.
You can use the AWS Managed policy “AmazonEC2ReadOnlyAccess” to allow describing the EC2 instances.
Create a role which can be used by Lambda as the execution role. The role applied to Lambda must at a minimum have;
Assume Role across accounts
|
|
The Resource listed in the above policy can be made into a list to define multiple accounts
For logging to cloudWatch (useful for audit and troubleshooting)
|
|
Ability to upload to S3 bucket
|
|
S3 access
Define a policy to allow the AWS Lambda function access to your S3 bucket
|
|
S3 considerations
Unless you have any contractual or regulatory requirements to retain x amount of logs, you could introduce a Lifecycle rule to the s3 bucket to remove objects older than x days.
Trigger : Amazon EventBridge event
Please use the following steps to define a schedule trigger to generate the log files
- On the AWS Console, navigate to CloudWatch Amazon EventBridge. Then select the Events | Rules
- Select the Create Rule button
- Select the schedule radio button and define your schedule. We used a cron expression 00 03 ? * * * This executed the code at 3am everyday of the week
- Select the add target button
- Choose Lambda function and then select your function from the drop down list
- Select the Configure details button
- Give the rule a meaningful name and description
- Select the Create rule button
Testing
To test your AWS Lambda function without using the event trigger, configure a test event and have nothing define in the json, e.g.
|
|
AWS Lambda settings
This one always pops up when I develop code to run on AWS Lambda
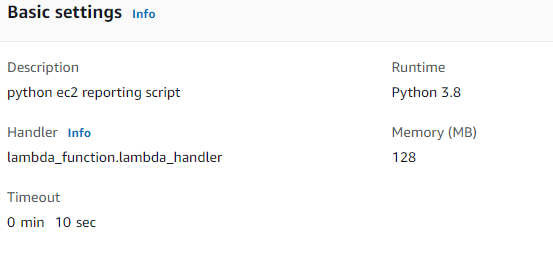
The key entry in that above screenshot is Timeout (actually they are all important this is just the one which will catch you out). The default value is 3 seconds. Consider that this function is describing instances across multiple accounts. The amount of time it takes is going to depend on many factors such as geographical locations, amount of instances to retrieve, number of accounts to gather from. That’s just a few off the top of my head, I am sure there are more. The maximum timeout is 900 seconds so you will need to split the functions if this is not sufficient.
Planned enhancements
Send the output as an email attachment. Under test.
Conclusion
So lets sum up. We have deployed a python script into AWS Lambda. Granted AWS Lambda access to S3, AWS CloudWatch and AWS STS so it can gain temporary credentials and assume roles across accounts. We have defined roles in other AWS accounts which allow the account which is executing the AWS Lambda function access to describe EC2 instances. We have then generated a csv file with specific values we requested and posted this to an S3 bucket.
Great stuff. As usual, feel free to ask any questions or let me know if you have any suggestions on how to improve the process. AWS is a constantly evolving landscape so change is inevitable. Oh almost forgot, link to the GitHub repository here.